Object Localization
Object Classification + Localization
Assume that an image has only one object. Try to classify an object and find a box around it.
Pipeline:
Image -> ConvNet -> Out (Features from the last layer) -> Softmax(Number of classes) - Classify
-> Linear Regression(b_x, b_y, b_h, b_w) - Bounding Box
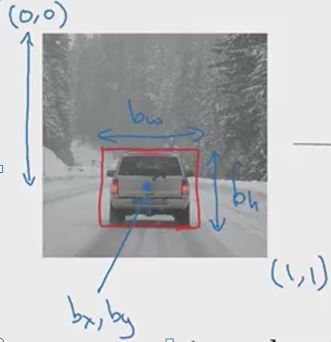
Upper-left Image corner = (0, 0)
Bottom-right Image corner = (1, 1)
\(b_x\) = 0.5, \(b_y\) = 0.7 - center of BB wrt image size, \(b_h\) = 0.3, \(b_w\) = 0.4 - BB’s height and width wrt image size.
Representation of the target label y for training.
Assume we have three classes for objects + one class for background (there’s no object):
1 - pedestrian; 2 - car; 3 - tree.
Target vector:
y = [p_c, b_x, b_y, b_h, b_w, c_1, c_2, c_2]
where
p_c - probabality that there is an object, box confidence;
b_x, b_y, b_h, b_w - bounding box;
c_1, c_2, c_2 - probabality which tells us what class of object is more probable.
For an image with an object, say a car vector y is:
y = [1 bx by bh bw 0 1 0]
If there is no object in the image then:
y = [0 x x x x x x x]
Box confidence pc = 0 and the other components doen’t matter.
Loss function
L(y_hat, y) = (y_hat_1 - y_1)^2 + ... + (y_hat_8 - y_8)^2 if y_1 == 1 (pc == 1)
L(y_hat, y) = (y_hat_1 - y_1)^2 if y_1 == 0 (pc == 0)
In practise L2 loss isn’t used. Instead for pc component (y_1) use Logistic Regression,
for BB components (y_2, y_3, y_4, y_5) use L2 loss and for c1, c2, c3 components
use Softmax loss.
Landmark detection

Image -> ConvNet -> Classification (Is it a face?)
-> Linear Regression (Predict coordinates of interesting points)
where l1x, l1y, ..., lnx, lny - coordinates of 1st, ..., n-th landmark point.
One important thing is that labels l1x, l1y and so on should be consistent across all images
(for example, (l1x, l1y) is always the left corner of the left eye, (l2x, l2y) is always the right corner of the left eye and so on).